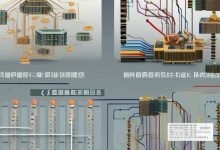
MapReduce 两次统计样例程序:解析大数据处理的关键步骤
MapReduce是处理大规模数据集的计算模型,它由两个主要阶段组成:Map(映射)和Reduce(归约),通过这两个阶段的协作,可以高效地对大量数据进行分布式处理,在实际应用中,有时需要对同一组数据进行两次统计,以获得更深入的洞察,本文将通过一个样例程序详细解析这一过程的关键步骤。

第一次统计:词频统计
Map阶段
在Map阶段,输入的数据被拆分成多个独立的块,每个块由一个Map任务处理,假设我们有一个文本文件作为输入,包含以下内容:
Hello world I am learning MapReduce MapReduce is powerful
Map函数的任务是将每行文本拆分成单词,并为每个单词生成一个键值对,键是单词本身,值通常是1(表示计数)。
| 输入文本 | 输出键值对 |
| Hello world | |
| I am learning MapReduce | |
| MapReduce is powerful | |
Shuffle和Sort阶段
Map任务完成后,输出的键值对会被Shuffle和Sort阶段处理,Shuffle阶段负责将所有相同键的值聚集到一起,而Sort阶段则将这些键值对按键排序。

Reduce阶段
Reduce函数接收到排序后的键值对列表,并对每个键对应的值进行合并操作,在这个例子中,我们将所有相同的单词的计数相加。
| 单词 | 计数 |
| Hello | 1 |
| world | 1 |
| I | 1 |
| am | 1 |
| learning | 1 |
| MapReduce | 2 |
| is | 1 |
| powerful | 1 |
第二次统计:按单词长度统计
Map阶段
在第二次统计中,我们需要根据单词的长度进行分类统计,Map函数的任务是为每个单词生成一个新的键值对,键是单词的长度,值是单词本身。
| 单词 | 输出键值对 |
| Hello | <5, Hello> |
| world | <5, world> |
| I | <1, I> |
| am | <2, am> |
| learning | <8, learning> |
| MapReduce | <9, MapReduce> |
| is | <2, is> |
| powerful | <8, powerful> |
Shuffle和Sort阶段

同样,Map任务完成后,输出的键值对会经过Shuffle和Sort阶段处理。
Reduce阶段
Reduce函数这次将对每个长度对应的单词列表进行合并操作,通常这里的合并就是简单地列出所有相同长度的单词。
| 单词长度 | 单词列表 |
| 1 | I |
| 2 | am, is |
| 5 | Hello, world |
| 8 | learning, powerful |
| 9 | MapReduce |
通过这两次统计,我们不仅得到了每个单词的出现频率,还了解了不同长度的单词分布情况,这种两次统计的方法在数据分析中非常有用,可以帮助我们从不同角度理解数据。
到此,以上就是小编对于“MapReduce 两次统计样例程序:解析大数据处理的关键步骤”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。